SAME: Uncovering GNN Black Box with Structure-aware Shapley-based Multipiece Explanation
1 Southern University of Science and Technology
2 The Hong Kong Polytechnic University
3 King Abdullah University of Science and Technology
4 Carnegie Mellon University
* Equal Contribution
(NeurIPS 2023 Poster)
Project Description
Post-hoc explanation techniques on graph neural networks (GNNs) provide economical solutions for opening the black-box graph models without model retraining. Many GNN explanation variants have achieved state-of-the-art explaining results on a diverse set of benchmarks, while they rarely provide theoretical analysis for their inherent properties and explanatory capability. In this work, we propose Structure-Aware Shapley-based Multipiece Explanation (SAME) method to address the structure-aware feature interactions challenges for GNNs explanation. Specifically, SAME leverages an expansion-based Monte Carlo tree search to explore the multi-grained structure-aware connected substructure. Afterward, the explanation results are encouraged to be informative of the graph properties by optimizing the combination of distinct single substructures. With the consideration of fair feature interactions in the process of investigating multiple connected important substructures, the explanation provided by SAME has the potential to be as explainable as the theoretically optimal explanation obtained by the Shapley value within polynomial time. Extensive experiments on real-world and synthetic benchmarks show that SAME improves the previous state-of-the-art fidelity performance by 12.9% on BBBP, 7.01% on MUTAG, 42.3% on Graph-SST2, 38.9% on Graph-SST5, 11.3% on BA-2Motifs and 18.2% on BA-Shapes under the same testing condition. Code is available at https://github.com/same2023neurips/same.
Paper
Code and Document
Code is released at: https://github.com/SAME2023NeurIPS/SAME
Method: SAME
Figure 1: Overview of Structure-Aware Shapley-based Multipiece Explanation (SAME) method. (a) Important substructure initialization phase aims at searching the single connected important substruc- ture. (b) Explanation exploration phase provides a candidate set of explanations by optimizing the combination of different important substructures. (c) The comparison of the final explanation with the highest importance score from the candidate set with the optimal explanation.
Experiments
Exp 1: Quantitative experimentsExp 2: Qualitative experiments
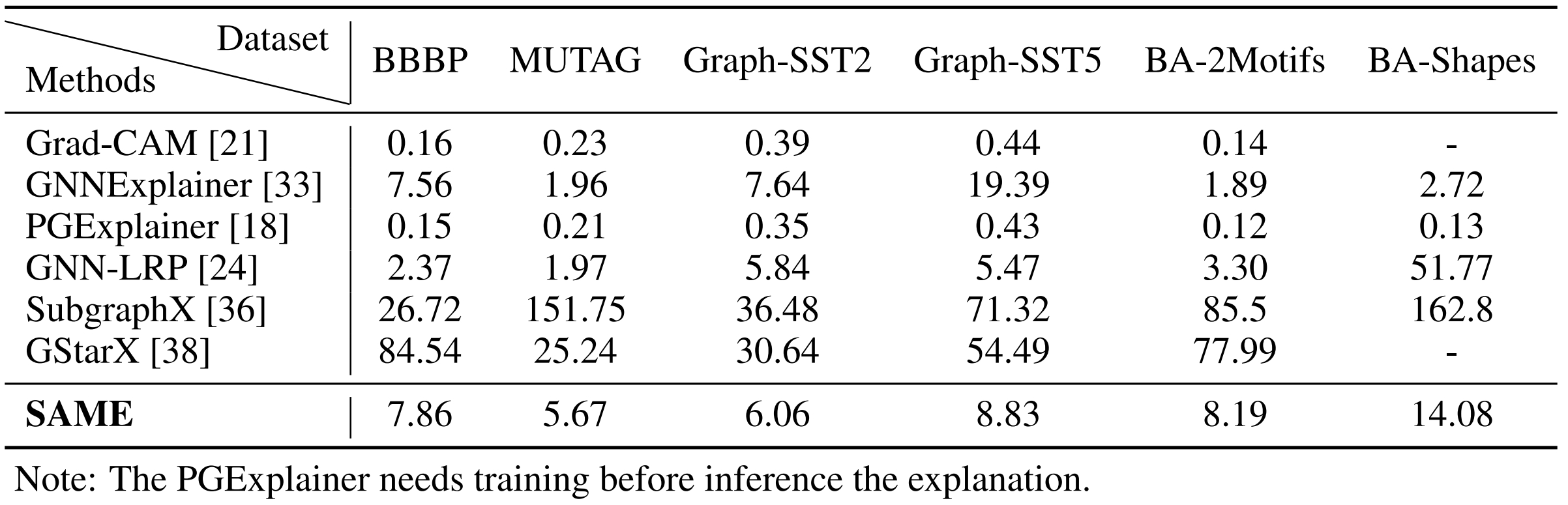
Experiment 1: Quantitative experiments


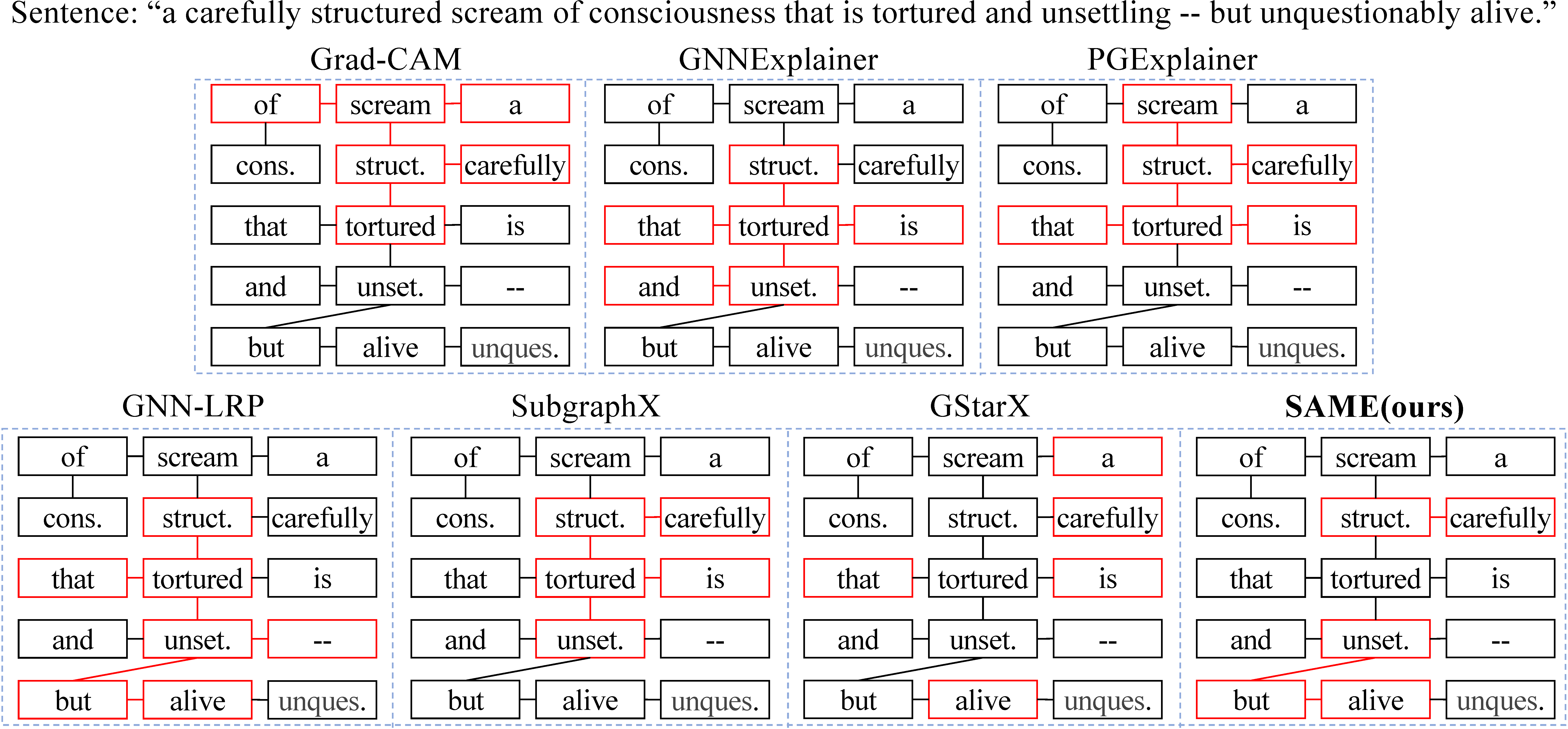
Experiment 2: Qualitative experiments